# Introduction
### 1. What is Database?
A **database** is an organized collection of data, so that it can be easily accessed and managed.\
You can organize data into tables, rows, columns, and index it to make it easier to find relevant information.
### 2. What is DBMS?
**Database Management System (DBMS)** is a software for storing and retrieving users' data while considering appropriate **security measures**. It consists of a **group of programs** which manipulate the database. The **DBMS accepts the request for data** from **an application** and instructs the o**perating system to provide the specific data.**
### **3. Need for DBMS**
* Creation of a database.
* Retrieval of information from the database.
* Updating the database.
* Managing a database.
It provides us with many functionalities and is more advantageous than the traditional file system in many ways listed below:
**1) Processing Queries and Object Management**:\
In traditional file systems, we cannot store data in the form of objects. In practical-world applications, data is stored in objects and not files.
**2) Controlling redundancy and inconsistency:**\
Redundancy refers to repeated instances of the same data. A database system provides redundancy control whereas in a file system, same data may be stored multiple times.
**3) Efficient memory management and indexing:**\
DBMS makes complex memory management easy to handle. In file systems, files are indexed in place of objects so query operations require entire file scans whereas in a DBMS , object indexing takes place efficiently through database schema based on any attribute of the data or a data-property. This helps in fast retrieval of data based on the indexed attribute.
A **D**ata **B**ase **M**anagement **S**ystem is a system software for easy, efficient and reliable data processing and management. It can be used for:
### **4. Difference between** DBMS and File system
| DBMS | File System |
| ----------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------- |
| DBMS is a collection of data. In DBMS, the user is not required to write the procedures. | File system is a collection of data. In this system, the user has to write the procedures for managing the database. |
| DBMS gives an abstract view of data that hides the details. | File system provides the detail of the data representation and storage of data. |
| DBMS provides a crash recovery mechanism, i.e., DBMS protects the user from the system failure. | File system doesn't have a crash mechanism, i.e., if the system crashes while entering some data, then the content of the file will lost. |
| DBMS provides a good protection mechanism. | It is very difficult to protect a file under the file system. |
| DBMS contains a wide variety of sophisticated techniques to store and retrieve the data. | File system can't efficiently store and retrieve the data. |
| DBMS takes care of Concurrent access of data using some form of locking. | In the File system, concurrent access has many problems like redirecting the file while other deleting some information or updating some information. |
### 5. What is DBA and its Functions
**DBA** stands for **Database Administrators** . DBA is used to **store and organize data**. The role may include capacity planning, installation, configuration, database design, migration, performance monitoring, security, troubleshooting, as well as backup and data recovery.
Functions of a **DBA** include
* **Schema definition**.The DBA creates the original database schema by executing a set of data definition statements in the DDL.
* **Storage structure and access-method definition.**
* **Schema and physical-organization modification**.The DBA carries out changes to the schema and physical organization to reflect the changing needs of the organization, or to alter the physical organization to improve performance.
* **Granting of authorization for data access.** By granting different types of authorization, the database administrator can regulate which parts of the database various users can access.
* **Routine maintenance**.
### 6. Difference Between Two-Tier And Three-Tier database architecture
**Difference Between Two-Tier And Three-Tier Database Architecture**
| S.NO | Two-Tier Database Architecture | Three-Tier Database Architecture |
| ---- | ------------------------------------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------- |
| 1 | It is a Client-Server Architecture. | It is a Web-based application. |
| 2 | In two-tier, the application logic is either buried inside the user interface on the client or within the database on the server (or both). | In three-tier, the application logic or process resides in the middle-tier, it is separated from the data and the user interface. |
| 3 | Two-tier architecture consists of two layers : Client Tier and Database (Data Tier). | Three-tier architecture consists of three layers : Client Layer, Business Layer and Data Layer. |
| 4 | It is easy to build and maintain. | It is complex to build and maintain. |
| 5 | Two-tier architecture runs slower. | Three-tier architecture runs faster. |
| 6 | It is less secured as client can communicate with database directly. | It is secured as client is not allowed to communicate with database directly. |
| 7 | It results in performance loss whenever the users increase rapidly. | It results in performance loss whenever the system is run on Internet but gives more performance than two-tier architecture. |
| 8 | Example – Contact Management System created using MS-Access or Railway Reservation System, etc. | Example – Designing registration form which contains text box, label, button or a large website on the Internet, etc. |
### 7. Database Language and Commands
Structured Query Language(SQL) as we all know is the database language by the use of which we can perform certain operations on the existing database and also we can use this language to create a database. SQL uses certain commands like Create, Drop, Insert etc. to carry out the required tasks.
**These SQL commands are mainly categorized into four categories as:**
1. **DDL – Data Definition Language**
2. **DQL – Data Query Language**
3. **DML – Data Manipulation Language**
4. **DCL – Data Control Language**
5. **TCL – Transaction Control Language**
6. **DDL(Data Definition Language) :** DDL or Data Definition Language actually consists of the SQL commands that can be used to define the database schema. It simply deals with descriptions of the database schema and is used to create and modify the structure of database objects in the database.
**Examples of DDL commands:**
* **CREATE** – is used to create the database or its objects (like table, index, function, views, store procedure and triggers).
* **DROP** – is used to delete objects from the database.
* **ALTER**-is used to alter the structure of the database.
* **TRUNCATE**–is used to remove all records from a table, including all spaces allocated for the records are removed.
* **COMMENT** –is used to add comments to the data dictionary.
* **RENAME** –is used to rename an object existing in the database.
7. **DQL (Data Query Language) :**
DML statements are used for performing queries on the data within schema objects. The purpose of DQL Command is to get some schema relation based on the query passed to it.
**Example of DQL:**
* **SELECT** – is used to retrieve data from the a database.
8. **DML(Data Manipulation Language) :** The SQL commands that deals with the manipulation of data present in the database belong to DML or Data Manipulation Language and this includes most of the SQL statements.
**Examples of DML:**
* **INSERT** – is used to insert data into a table.
* **UPDATE** – is used to update existing data within a table.
* **DELETE** – is used to delete records from a database table.
9. **DCL(Data Control Language) :** DCL includes commands such as GRANT and REVOKE which mainly deals with the rights, permissions and other controls of the database system.
**Examples of DCL commands:**
* **GRANT**-gives user’s access privileges to database.
* **REVOKE**-withdraw user’s access privileges given by using the GRANT command.
10. **TCL(transaction Control Language) :** TCL commands deals with the transaction within the database.
**Examples of TCL commands:**
* **COMMIT**– commits a Transaction.
* **ROLLBACK**– rollbacks a transaction in case of any error occurs.
* **SAVEPOINT**–sets a savepoint within a transaction.
* **SET TRANSACTION**–specify characteristics for the transaction.

### 8. **Instances/Schema/Sub schema** :
#### **-> Instances in DBMS**
It is the **snapshot of the database taken at a particular moment**. It can also be described in more significant way as the collection of the information stored in the database at that particular moment. Instance can also be called as the database state or current set of occurrence due the fact that it is information that is present at the current state.
**-> Schema in DBMS**
It is the **overall description or the overall design of the database specified during the database design.** Basically, i**t displays the record types(entity), names of data items(attribute)** but not the relation among the files.
**Interesting point is the values in schema might change but not the structure of schema.**
#### **-> Sub schema in DBMS**
It can be defined as the subset or sub-level of schema that has the same properties as the schema. It Identifies subset of areas, sets, records, data names defined in database that is of interest to him. Thus a portion of database can be seen by application programs and different application programs has different view of data.
### **9.** What is Data Abstraction
Data Abstraction refers to the process of hiding irrelevant details from the user.
### 10. What are its three levels of Data Abstraction
There are mainly three levels of data abstraction and we divide it into three levels in order to achieve Data Independence. Data Independence means users and data should not directly interact with each other. The user should be at a different level and the data should be present at some other level. By doing so, Data Independence can be achieved.
1. View Level
2. Conceptual Level
3. Physical Level

**View Level or External Schema**
**This level tells the application about how the data should be shown to the user**. **Example:** If we have a login-id and password in a university system, then as a student, we can view our marks, attendance, fee structure, etc. But the faculty of the university will have a different view. He will have options like salary, edit marks of a student, enter attendance of the students, etc. So, both the student and the faculty have a different view. By doing so, the security of the system also increases.
**Conceptual Level or Logical Level**
**This level tells how the data is actually stored and structured**. We have different data models by which we can store the data. **Example**: Let us take an example where we use the relational model for storing the data. We have to store the data of a student, the columns in the student table will be student\_name, age, mail\_id, roll\_no etc. We have to define all these at this level while we are creating the database. Though the data is stored in the database but the structure of the tables like the student table, teacher table, books table, etc are defined here in the conceptual level or logical level.
**Physical Level or Internal Schema**
**As the name suggests, the Physical level tells us that where the data is actually stored i.e. it tells the actual location of the data that is being stored by the user. The Database Administrators(DBA) decide that which data should be kept at which particular disk drive, how the data has to be fragmented, where it has to be stored etc.**
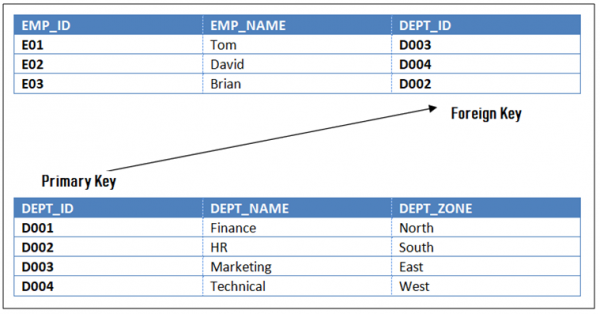
### 11. Referential Integrity Rule in RDBMS
A **primary key** is used to ensure data in the specific column is unique.\
A **foreign key** is a column or group of columns in a relational database table that provides a link between data in two tables.
Referential Integrity Rule in DBMS is based on **Primary and Foreign Key.** Th**e Rule defines that a foreign key have a matching primary key**. Reference from a table to another table should be valid.
**Referential Integrity Rule example:-**
**Employee**
| EMP\_ID
| EMP\_NAME
| DEPT\_ID
|
| ----------------------------------- | -------------------- | ------------------------------------ |
\
**Department**
| DEPT\_ID
| DEPT\_NAME
| DEPT\_ZONE
|
| ------------------------------------ | --------------------- | --------------------- |
\
The rule states that the **DEPT\_ID** in the Employee table has a matching valid **DEPT\_ID** in the **Department** table.
To allow join, the **referential integrity rule states that the Primary Key and Foreign Key have same data types.**
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://soumyajit4419.gitbook.io/ds-algo/dbms-notes/introduction.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.